People have been talking about machine learning for quite a while now but is it really worth the hype it attracts? Users believe that the high-performance measures for a particular task indicate good quality of a model. However, due to problems with data annotation and limited data sources in a community, it turns out that models tend to “memorize” datasets and even small shifts in data distribution lead to enormous mistakes in the prediction output. This phenomenon is present both in computer vision and natural language processing problems.
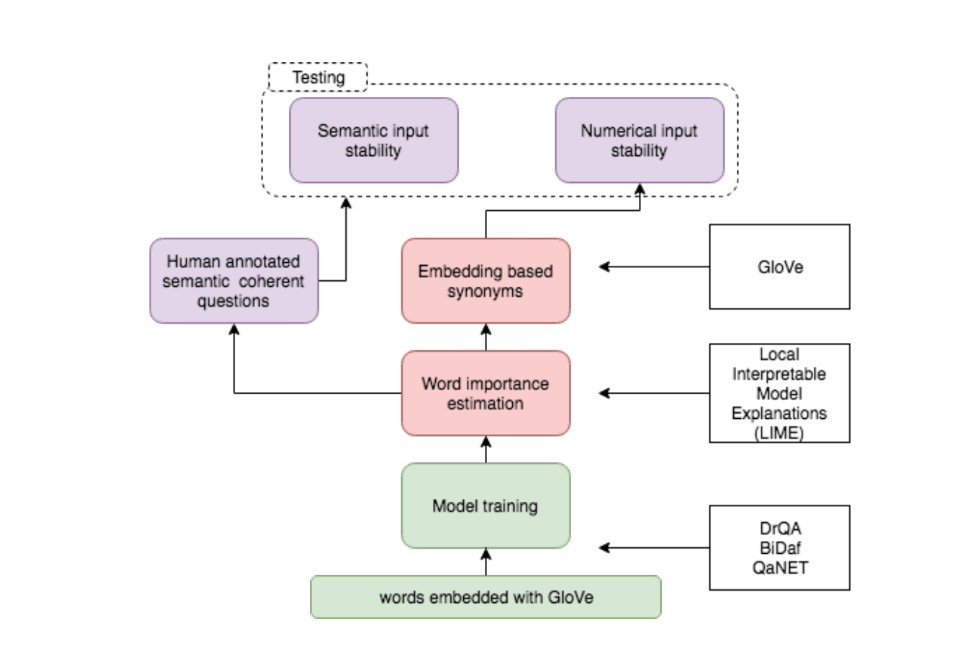
In cooperation with MI2 DataLab at Warsaw University of Technology, we have conducted a couple of experiments that highlight drawbacks of popular models perceived as state-of-the-art (or almost state-of-the-art), especially, in the NLP field. The results were presented at EMNLP workshop during Blackbox NLP (https://blackboxnlp.github.io/) and NeurIPS workshop on Interpretability and Robustness in Audio, Speech, and Language.
Question answering – can machines really comprehend text?
The task of question answering in its most popular form is focused on the extraction of answer span from the provided text based on the question asked. Recently, NLP community was focused on reaching human performance on SQuAD dataset, which constructed from Wikipedia paragraphs and human-annotated questions. The dataset has over 100 000 question-answer pairs.
SQuAD schema
Paragraph
One of the most famous people born in Warsaw was Maria Skłodowska-Curie, who achieved international recognition for her research on radioactivity and was the first female recipient of the Nobel Prize. Famous musicians include Władysław Szpilman and Frédéric Chopin. Though Chopin was born in the village of Żelazowa Wola, about 60 km (37 mi) from Warsaw, he moved to the city with his family when he was seven months old. Casimir Pulaski, a Polish general and hero of the American Revolutionary War, was born here in 1745.
Question 1
What was Maria Curie the first female recipient of?
Answer 1
Nobel Prize
Question 2
Who was one of the most famous people born in Warsaw?
Answer 2
Maria Skłodowska-Curie
These problems are solved as a classification task over the span of tokens from context. An exemplary architecture is shown in on figure below – it presents a well-known architecture of BiDAF model:

Well, it turns out that machines do not understand a lot, after all…
In our three consecutive studies, we conducted tests to verify the robustness and overstability of Question Answering models:
- Case 1: We slightly change the question preserving its semantic meaning
- Case 2: We change the question a lot, so its meaning is severely altered
We assume that in case 1 the answer returned by the model should be the same whereas in case 2 we assume that answer should be at least wrong – in ideal case scenario the model should be trained to give “no answer” probability.
Let’s focus on Case 1 for now
We define two types of stability: semantic and numeric. Case 1 in our analysis is reflected in the semantic stability – even though we change question in Q&A model, we expect the same output. Words from questions (and contexts as well) are represented as embeddings. In order to test numeric stability, we decide to change selected words from the question for their closest neighbors in embedding space. It must be noted that although words are close to each other in embedding space, they might have contrary meanings – for instance, “left” is close to “right” or “victory” is close to “defeat”.
An example of such analysis is shown below – the original question is replaced with the semantically equivalent word “citizen”, while its closest word in embedding space is ‘those’( which does not make a lot of sense). For a benchmark, we also tested questions with the word “random”. We chose a word based on its importance calculated by LIME – a known method for black box estimation of feature contribution.

It turns out that for each of these changes the performance of the model dropped dramatically i.e. by 30-40 p.p. However, the accuracy for numeric changes dropped less than for semantically coherent questions.
These results clearly show that developed models are very vulnerable to any type of change and they possibly learn correlations between some selected words and correct ground truth. Once we train one of the analyzed models in the adversarial setting by enriching training dataset with questions for which we randomly remove words, the systems are more immune to adversarial changes and performance on semantically similar question increases.
Case 2: how much should you ask?
When we think about machine learning models, we often try to align their behavior with human behavior. It means that we have some expectations about the predicted output based on how we understand an image or a question. It turns out that what is not understandable for humans, might be just enough for a machine learning model.
Once again, in another research conducted this year, we estimated the most important word in the question, based on LIME coefficients. We subsequently removed words from least to most important and checked prediction accuracy. In the example below, we can see that the answer remains the same, even though we reduced the question… to a single word “type”. We assumed that with such reduced question the model would return a wrong prediction.

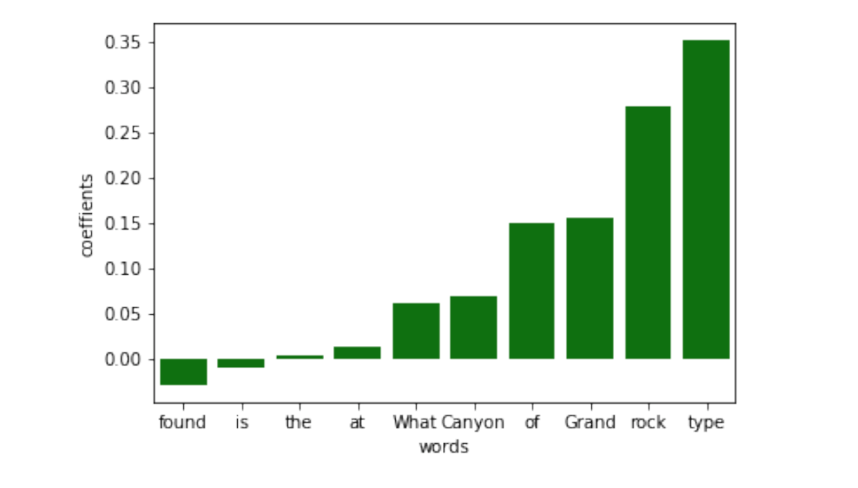
Lime coefficients for question words.

In most cases, we could remove up to 80-90% of question words and still have a correct prediction.
Is there any hope for robustness of machine learning models?
Model robustness verification and adversarial stability training is a growing research area. Every time the community reaches state-of-the-art performance in a certain task, more and more validation frameworks are deployed (some interesting references can be found below).
Widely accessible datasets usually include toy examples but there is hope that these models would serve in more significant areas of life – like medicine or law. Their vulnerability is a major drawback that decreases human trust and in a worst-case scenario can even lead to risky decisions. Model auditing is like good detective work – if you find the cause of instability of the machine learning model and you can improve its robustness, you have a case cracked!
References
1.Shi Feng, Eric Wallace, Mohit Iyyer, Pedro Rodriguez, Alvin Grissom II, and Jordan L. BoydGraber. Right answer for the wrong reason: Discovery and mitigation. CoRR, abs/1804.07781, 2018.
2. Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer open-domain questions. In Association for Computational Linguistics (ACL).
3. Robin Jia and Percy Liang. Adversarial examples for evaluating reading comprehension systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2021–2031. Association for Computational Linguistics, 2017.
4. Pramod Kaushik Mudrakarta, Ankur Taly, Mukund Sundararajan, and Kedar Dhamdhere. Did the model understand the question? CoRR, abs/1805.05492, 2018.
5. Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Semantically equivalent adversarial rules for debugging nlp models. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 856–865. Association for Computational Linguistics, 2018.