Continuous Hidden Markov Models suffered from a bias considered a feature, not a bug – the system assumed that every phenomenon observed is represented by standard parameterized distributions, effectively limiting the accuracy of the approach. Well – not anymore!
Machine learning is founded on two basic elements – the models and the datasets. With the latter being increasingly available, reaching the next level and breaking the limitations of AI-based solutions seems merely data-based.
On the other hand, the models are not perfect, yet every improvement comes with a significant boost in performance and a reduction of energy consumption. That’s why this year’s Tooploox contribution for Neural Information Processing Systems (NeurIPS) is about improving the model. Or rather – tackling the bias considered “a feature not a bug.”
What is a Hidden Markov Model (HMM)
The Hidden Markov Model is a popular machine learning tool used in the analysis of time series data. The approach has been successfully applied in numerous fields, including finance, speech recognition, and computational biology, among others.
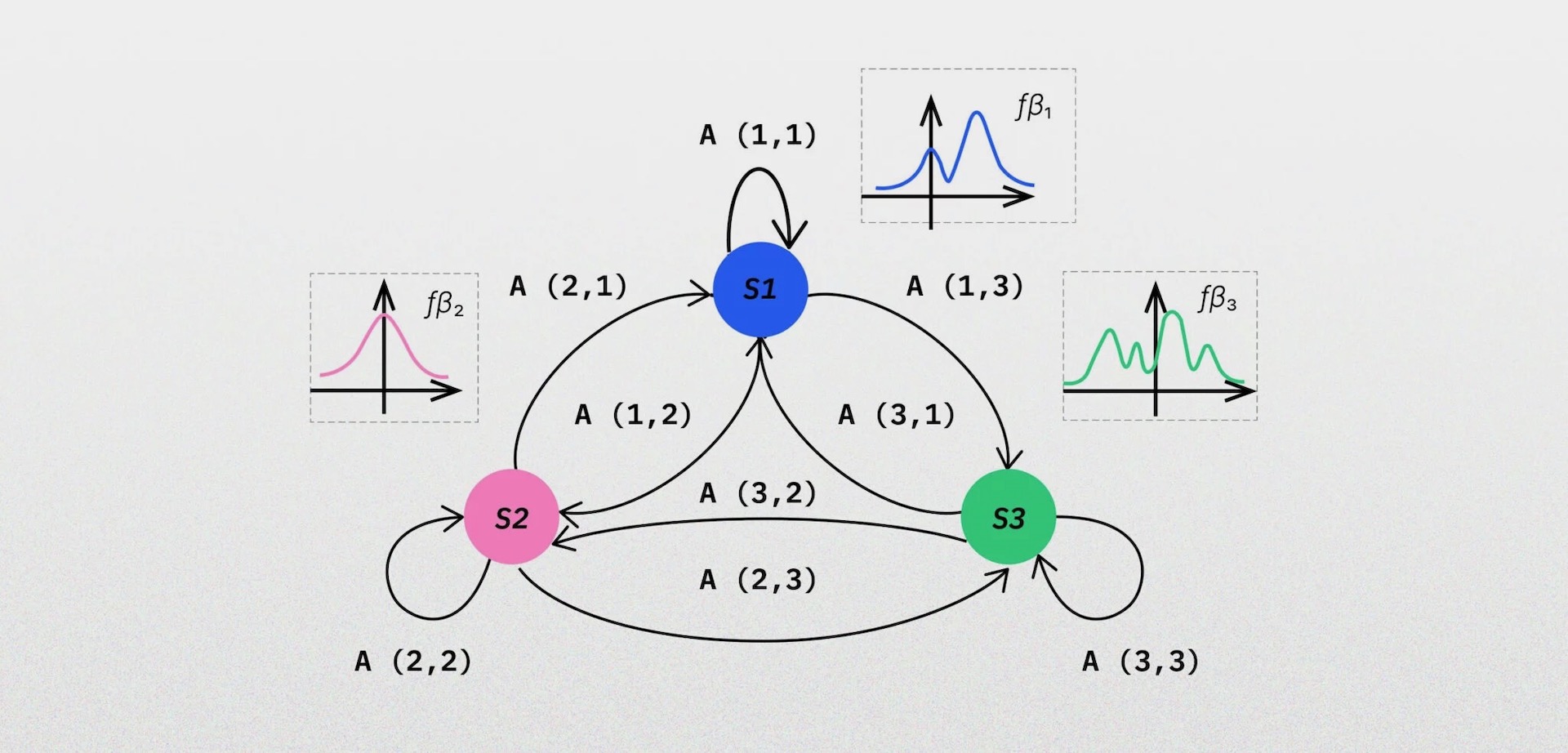
The tool is used to observe a particular “process” where there are some obscure (hidden) states (or factors) influencing it. The goal of the model is to spot that factor and estimate its impact on the whole system. The number of impacting factors doesn’t matter for the model, making it perfect for analyzing complex systems.
The Hidden Markov Model’s Limitations
Hidden Markov Models suffer from several limitations. One of them is the built-in assumption that every observed phenomenon, be that energy usage, stock prices or anything else where the system is applied, follows standard parametrized distributions. In other words – all observable reality follows, in most cases, the most popular Gaussian distribution – which is simply not true.
For example, the system may be used to predict the energy consumption of a household, with every home appliance mapped and included. In this system, every machine follows its own pattern. The refrigerator is consuming a stable amount of energy 24/7. The washing machine is run once every few days, and the dishwasher follows different programs to deal with multiple types of dinners to clean up after.
With every machine listed above being forcefully described using gaussian distribution, the energy consumption prediction becomes flawed. When done on the scale of a whole city, the miscalculations may stack up to thousands of kilowatt-hours.
Tooploox’s contribution
The Gaussian model is common and sufficient in a plethora of use cases. Yet getting a 100% accuracy is possible only using a normalized model.
The Tooploox team, consisting of Paweł Lorek, Rafał Nowak, Tomasz Trzciński and Maciej Zięba, managed to replace the assumption of the standard parameterized distributions hard-coded into hidden Markov models with Normalizing Flows.
What are Normalizing Flows
Normalizing Flows are common in statistics and mathematical modeling. They are used to model probability distribution using changing variables, and by that induce greater flexibility than gaussian modeling.
Normalizing Flow can be used to deliver extremely precise probability estimations, effectively much more complex than Gaussian distribution and other parametrized families of distribution. In the context of energy usage, applying the Gaussian model delivers accurate predictions for a typical day. yet it omits local spikes, for example the transmission of football matches and sudden surge in demand during the breaks.
The effect
The approach was validated against classic Hidden Markov Models utilizing Gaussian mixture observation densities. In order to examine the quality of our approach compared to the reference methods we proposed synthetic examples with known states and non-gaussian densities.
Our model was able to identify the states correctly and adjust to the given distributions compared to the selected baselines. We also used some real time-series datasets from several domains (both univariate and multivariate). We achieved significantly better results compared to Gaussian Hidden Markov Models in terms of likelihood values, which is standard measure for evaluating probabilistic models in such scenarios.
Possible applications
The greater accuracy makes this approach much more applicable to nearly any situation where the standard Hidden Markov Model would normally be used. Among possible use cases one can name:
- Time series data analysis – adjusted to non-gaussian power consumption distribution for various home appliances, stock prices or basically anything else. The model can also be used to spot patterns in flowing data, for example to annotate a speaker in the recording of a panel discussion.
- Linear data scanning – the model can be used to search for hidden patterns in a series of data that is not exactly a time series – for example, a DNA chain or a text. In a DNA chain it can search for the repeating patterns that lie beneath. An interesting example can be in a plagiarism-check, done by recognizing the writing style of a particular writer, spotting the parts of a text delivered by a ghostwriter, or copied from somewhere else.
- Time series data prediction – the model can be used to deliver more accurate predictions of time series data, including energy or utilities use. Apart from delivering an analysis of the factors impacting the observed phenomenon, it can also provide predictions of future information.
The paper can be found on Arxiv and will be presented during the NeurIPS conference.
Summary
The research has been prepared for the Neural Information Processing Systems (NeurIPS) 2022 conference in New Orleans. It is the thirty-sixth edition of one of the most globally renowned and prestigious research conferences on Machine Learning.
The conference itself is an interdisciplinary event, bringing together researchers from machine learning, neuroscience, statistics, optimization, computer vision, natural language processing, life sciences, natural sciences, social sciences, and other adjacent fields.
Initially the conference was more focused on natural, biological neural networks, with artificial neural networks being only one of the components. Yet with the emergence of machine learning, the approach toward artificial intelligence and building artificial neural networks has dominated the event.
This is not the first time Tooploox has participated in the NeurIPS conference. The company had the privilege to show two Tooploox-affiliated papers in 2021. The papers were focused on delivering more precise predictions and reducing the energy consumption of artificial neural network-based systems. More about these papers can be found in this corresponding Tooploox blog post.