This is an overview of the visit at NIPS 2016 workshops in Barcelona, December 9-10th, 2016.
At Tooploox, we try to stay ahead of the crowd when it comes to data science and machine learning. This is why we organize our reading clubs, where we discuss together recent papers published at top-tier conferences. This is why we have our tech talks with presentations of current computer vision, natural language processing and audio analysis topics. And this is why we attend the biggest machine learning conferences around the world, such as Neural Information Processing Systems (NIPS) conference. This year, NIPS was hosted in a beautiful convention centre in sunny Barcelona, Spain. It was a massive event that brought together almost 6’000 machine learning scientists and practitioners from all over the place. The list of guests included ML “celebrities” like Yann LeCun , Yoshua Bengio and Ian Goodfellow (here is a link on the Generative Adversarial Networks he gave).
To see how big it was, just imagine some 10 rooms like the one below, all full of data science geeks and machine learning lovers ;-)

I have visited several workshop areas and below you can find the overview of the most interesting talks and posters I saw there (it’s my subjective assessment, so don’t ):
Modelling documents with Generative Adversarial Networks
This is a paper from Aylien – a NLP startup from Ireland that works mostly on the tools to extract meaning from the Web. The clue of the paper is the unsupervised method for document modelling using Energy-Based variation of GAN.
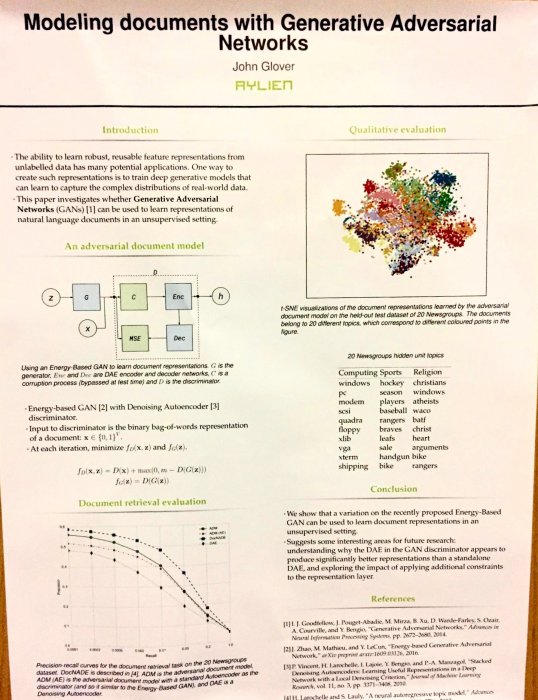
Trusting SVM for Piecewise Linear CNNs
This is a paper from Oxford (co-authored by Andrew Zisserman) on mixing SVMs with a modified CNN. Overall, it seems to be an overcomplicated approach to a standard approach (pretrained CNN outputs + SVM). Full paper available here.
ESE: Efficient Speech Recognition Engine with Compressed LSTM on FPGA
Paper from Stanford on speeding up speech recognition using pruning of LSTM modules in neural networks and hardware (FPGA) optimisation. Full paper available here.

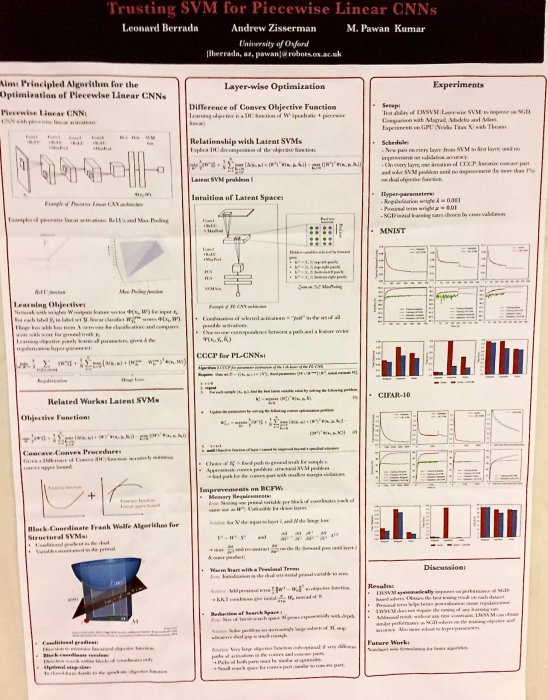
Efficient Stochastic Inference of Bitwise Deep Neural Networks
Stochastic approach to binarization of weights in deep neural networks. Full paper available here.
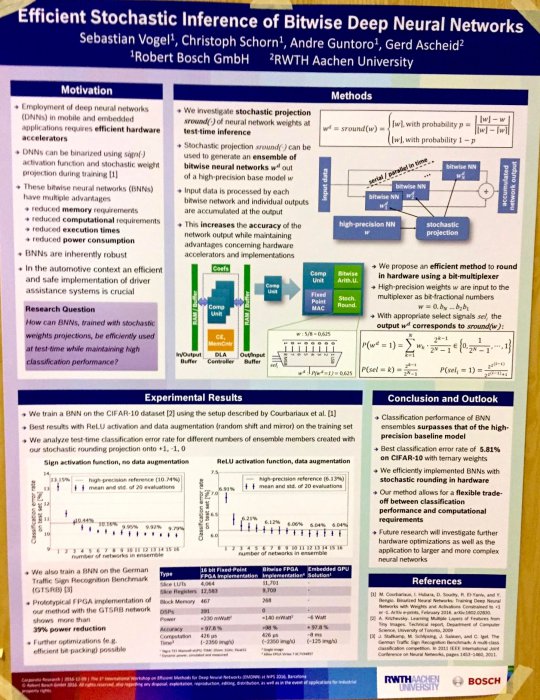
Pruning Filters for Efficient ConvNets
The main idea of the paper is to prune filters instead of the weights. Pruning occurs once with just one retraining (instead of the iterative approach). Prune filters across different layers. Full paper available here.
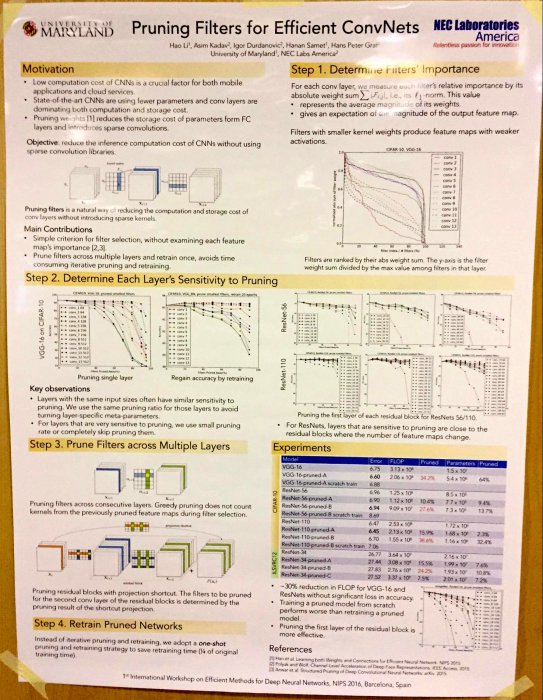
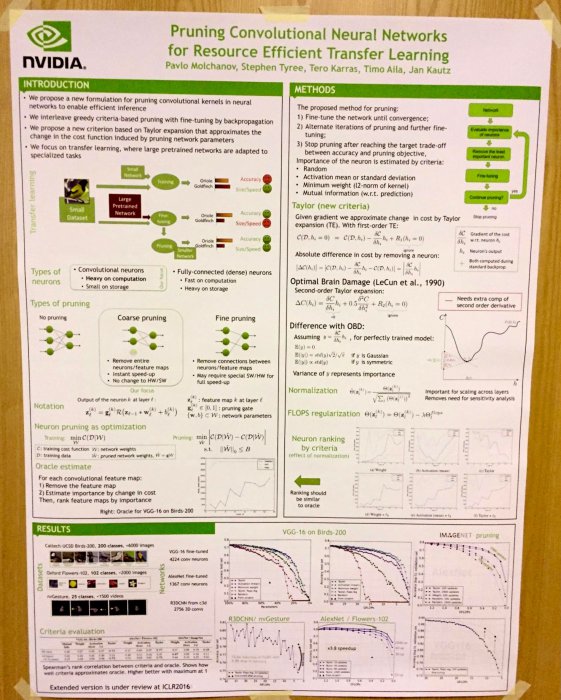
Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning
A combination of various pruning techniques (pruning & retraining, Taylor expansion for cost function change approximation, etc.). Full paper available here.
Other interesting reads about NIPS:
https://blog.ought.com/nips-2016-875bb8fadb8c#.r7kdp3vpi
Graphics by Anna Langiewicz