aka how to boost ypur work creativity

What happens when you have some cool idea in your head you would really like to explore, but you’re also very engaged in a client project and have little time for validating it? You initiate a hackathon!
As Magda Tuła noticed in the previous hackathon-themed entry, internal hackathons bring a lot of benefits to companies. From the developer’s/researcher’s perspective, I can add that intensive work in a novel and super short-term project can actually refresh your mind, boost your creativity and positively impact your way of working when you come back to your regular project. Moreover, as you have a chance to cooperate with specialists from other technologies, it is quite probable that you will come across some cool tool/library/pattern or even programming language that you didn’t know but would like to learn more about.
Last but not least, hackathons are definitely positively related to personal development. Whether you want to get to know some cutting-edge technical solution to a well-known problem, or aim to explore a topic that has an impact on the everyday life of many people and their problems, this is a space where you can start. No strings attached, but if you enjoy the outcome of your work, you may end up delving into the whole new domain of technology or research direction.
Research & Development – two branches where the magic happens
At Tooploox, we value both of these domains a lot! Most hackathon projects fall into the development category, as their output is some kind of working demo/ PoC that the audience can try out. However, we didn’t want to stop there. It’s enough to say that only this year we got 9 of our papers accepted for various tracks at A/A* conferences and we love applying our scientific findings in the client projects. To promote the interdisciplinary character of our company, we let the Hackathon ideas to be both of research or development type. This way, we can get together and brainstorm about the exciting research prospects and support their development.
Furthermore, having both research and development representatives involved in the hackathon, we can learn from each other’s experience, observe how our way of work differs and have a chance to establish the real R&D interdisciplinary teams.
How did we do it?
Tooploox Hackathon 2019 happened at the end of October and gathered a lot of participants around some exciting projects. We spent roughly 20 hours over 2 days on transforming foggy concepts in our heads into functioning demos, meaningful results and informative metrics. We invited MicroscopeIT specialists to actively participate in the event and we managed to establish one cross-company team.
During the preparation phase, we invited Plooxies to share their hackathon ideas in a common place, so each of us could come up with a project or join the existing one. Even though not all of the concepts materialized during the hackathon, some of them are still in our pipeline as research ideas that we can investigate either through self-learning activities or as part of our day to day job while they actually help us to a better company.
This year, we had 6 projects which attracted over 25 people.
Two of them were research projects – one of them was dedicated to exploring brand new directions of the research that is already carried out at Tooploox and the other one involved researchers investigating different modalities to focus on tackling a multi-modal research problem.
In the development section, we had two projects that required a specialized hardware (HoloLens and EEG from OpenBCI) whereas the remaining two were centered around making life more efficient with new software tools. Some idea owners prepared more detailed descriptions of their projects, including challenges they faced and the outcome of their work.
So check them out below!
Hololens – an augmented reality for learning new languages
As we are progressing in tightening our professional relationship between Microscope IT and Tooploox, we, as Microscope IT members, were excited to join the common hackathon initiative.
Our idea was to create an immersive application that helps in the early stages of learning a new language. As most of you probably know, when learning a new language, we usually start with words that we find in our surroundings, like those coming from the category of furniture or household appliances. To make this experience fun, interesting and interactive, we decided to utilize Hololens headset and neural networks. The outcome of our work is a Unity application deployed on Hololens that is able to detect common objects and tag them in the 3d space. It also has an additional feature – when you click on the detected object, you can hear it pronounced!
As our project required interdisciplinary skills, the technology behind our solution can be divided into the following parts: AI, Backend and Hololens. We used Keras implementation of YOLO model for the object detection and recognition. We didn’t perform any additional training and only used the official model checkpoint originally trained on the COCO dataset. To connect all the pieces together, we set up a Flask server for YOLO inference deployed on Azure and experimented with Azure Cognitive Services for adopting the speech-to-text feature. The Hololens part was crucial in the whole solution and required supporting various components. We needed to make sure that Hololens allows to capture photos of the current view and supplies the head position at a given timestamp. Then, the photos would be sent to the backend for processing and the 2D annotation of the recognised object would be returned. As the user continues his walk in the Hololens, the device runs a background service for estimating the scene geometry.
This feature, along with the already mentioned 2D annotations and head position data, enables retrieving exact 3D positions of the items. When they are obtained, the holograms are spawned in the calculated positions and then automatically follow scene geometry when the user moves. It means that when some item is recognized, its frame won’t move as you change your perspective, but it will continue to be placed around the item. On top of that, when a gesture (similar to pinching) is activated, the hologram closest to the center is picked and its name in the foreign language is played. Crazy.
We also have some ideas about extending our current solution. We would like to support more languages (currently it only works for English) and enable detection of more classes of objects (to overcome the limitations of the COCO dataset). Furthermore, it would be cool to augment the software’s functionality and add the possibility of learning more words by spawning holograms of different objects. We also came up with the idea of turning the whole learning experience into the game mode – one could for example choose a scenario where he has to find a particular object in a room, match words and objects in a room or guess a word for a randomly spawned hologram.
Brain-Computer Interface with EEG
The idea we’ve been thinking about for some time was to have some cool way to control devices. And in the end, is there anything more awesome than controlling something with your mind? Our goal for this project were to create a Brain-Computer Interface with reliable controls and do some awesome stuff with it.
We started with exploring already existing commercial-use EEG-based systems that would allow us to place the sensors on our heads and monitor the quality of a signal through an interface. We considered various devices – from toy-level stuff like Matell’s BrainFlex to even research-level devices. After careful consideration, we decided to go with the OpenBCI hardware “DIY Neurotechnologist’s Starter Kit”. Assembling EEG device was our first challenge. We had to 3D print the headset wireframe – a task in which we miserably failed (mostly due to its size and shape complexity), so we had to improvise a bit. With a little help of few cardboard boxes and meters of tape later, we created something. Let me introduce you to UltraCortex Headset – made from 100% recycled cardboard

It turned out that our cardboard-based headset was good enough for our project – it “only” required careful adjustments and sensor placement and little to no movement in order to get clean consistent readings.
The next major challenge was to come up with the idea that would be pretty painless to implement given our limited experience with EEG and brainwave analysis. We spent some time carrying out a few experiments and analysing what could be useful and what we could achieve before the hackathon ends. It resulted e.g. in “think about pepsi” experiment:
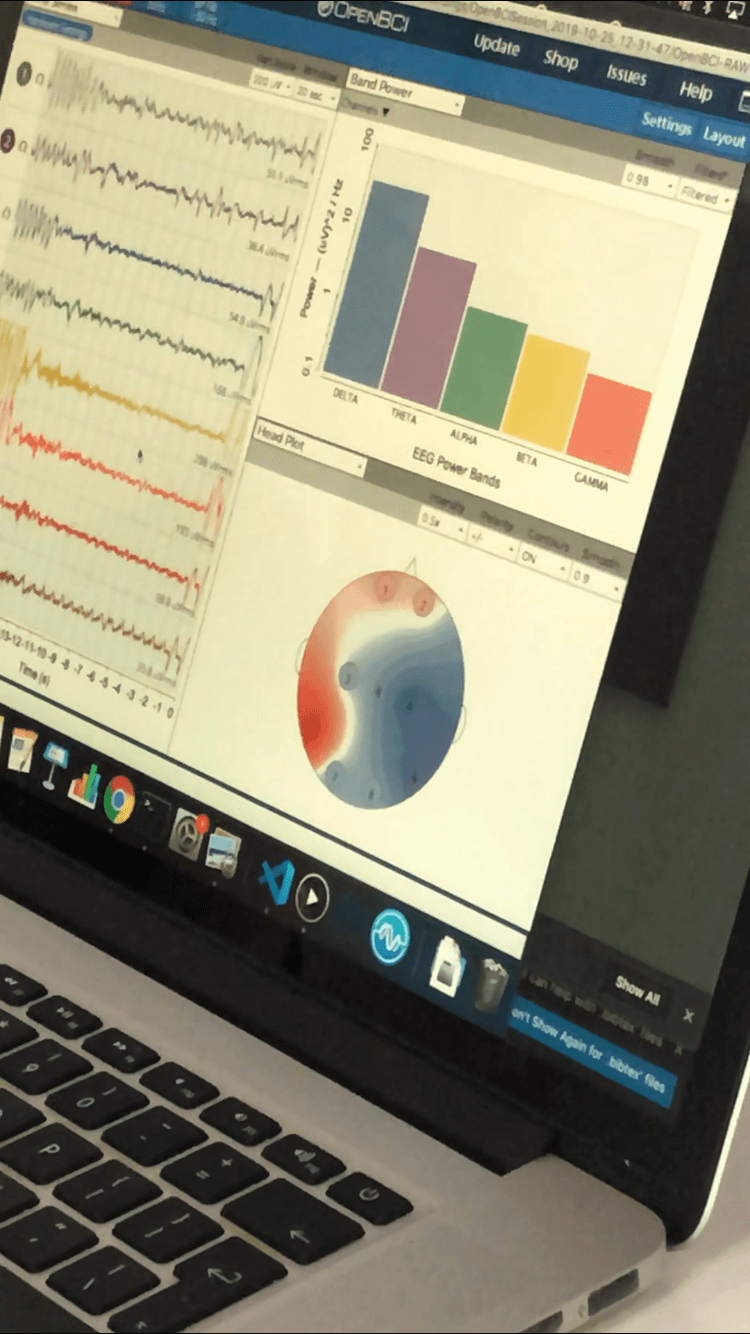
After few trials and errors we decided to go with motor cortex analysis in order to develop an interface the could control things by thinking about moving right or left hand. As one part of our team explored the possibilities to implement such a scheme from scratch, others conducted a few experiments on OpenVIBE software, that allowed us to execute few scenarios related to motor cortex that were similar to our objective. To have a fully working brain-computer interface, we needed to have a model adjusted to our particular task. Therefore, we created a dataset from two recordings coming from two subjects, where each of them would have to think about raising their left or right hand for a certain amount of time. It wasn’t as easy as it sounds, because it required “kinetic” thinking rather than visualisation and a lot of consistency about how we were imagining raised hand.
Also, we needed to take into account that this pattern may vary across individuals. At the end, we managed to have a custom model that could sometimes guess the right hand, but it’s really hard to tell if it was kind of random or just the way of thinking was hard to reproduce in tests. We had more success with OpenVIBE experiments where we could get consistent results proving that motion cortex was correctly used. Final result wasn’t as spectacular as we imagined it could be (f.e. mind controlled drone) but still we’re very proud of it, having in mind (pun intended :)) that most of us came with virtually zero experience in this field. We came from zero to hero – from the place where we didn’t even have a headset to the point where we had the entire BCI pipeline implemented and we could actually evaluate the quality of our models.
Still, looking back, we could have a better result – e.g. we would base our reading on more independent reading – left and right hand imagining have very similar waveform, while e.g. imagining movement and remembering something is much more easily distinguishable.

Multimodal YT
The problem of sentiment analysis might seem rather worn out. It is not surprising to anyone that machine learning can predict the characteristics of the given text, especially if the training data is available. However, in Tooploox we noticed that there is a strong business need for sentiment analysis that achieves good results in social media content, especially the one generated by users. It is oftentimes needed in automatic tracking of opinions in the e-commerce business, but also more substantial hate speech recognition. We also noticed another important thing: Internet users often comment on a particular story or video so their comment is put in context and this context defines the sentiment. We defined several classes: amusement, admiration, surprise, anger, disapproval, compassion, joke, hate, neutral and not relevant.
It turned out that it is extremely hard for annotators to distinguish between all of these classes, probably due to…high level of subjectivity.
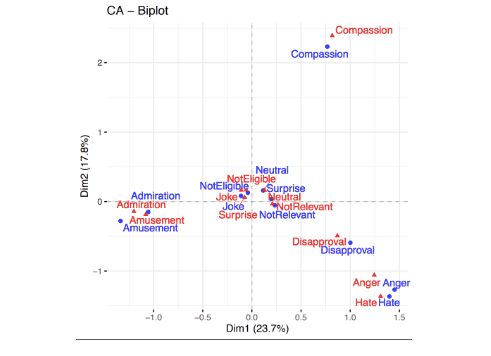
Prior to the hackathon, we collected a sample of 15 000 comments from YouTube video and hired two annotators to subjectively determine the comment taking into consideration the video. We checked the agreement between the annotators and we resolved disagreements with the help of super annotator.
While analyzing the dataset, we noticed some phenomena about the language used in social media that supported our hypothesis about the necessity of including context in the model.
- Firstly, people can be really cruel once they are anonymous, and we saw a lot of hateful comments like “hahaha” or “good for you!” when someone was actually getting hurt.
- Secondly, there are a lot of irrelevant comments that should be filtered out or classified to the separate group. These comments have nothing to do with the YT video itself, but they fall into the category of political manifesto, bot-generated content or some random Internet rants.
- Thirdly, the specifics of the Internet language include abbreviations, jive talk and many non grammatical sentences that need special representation trained on social media jargon.
Unfortunately, we did not manage to super-annotate all samples before the hackathon, so the number of training examples was limited. We trained two models: simple textual baseline, where text was embedded with pretrained ELMo embeddings and multimodal model, where we combined embedded comments with features extracted from the videos with the help of C3D model. Results of these two simple models initially confirmed our hypothesis that sentiment classification needs contextual information – we conclude based on confusion matrix and analysis of classes that we consider similar.
The differences in AUC metrics between text and multimodal models are also visible, although for both models the results are not satisfactory-the AUC are around 0.6-0.7, which is below sentiment classification baseline for other types of data. However, it must be noted that there is no real benchmark in our case, because we train models on a new dataset. For future works we want to redefine multimodal architectures and prepare more relevant representations of textual data. If you are interested in non standard approach to sentiment analysis in e-commerce, let us know!
And?
As proven above: we truly benefit from hackathons at Tooploox. Not only new great ideas are being explored, we can also validate our work together while team-building and bonding. Tooploox Hackathon 2020 is definitely gonna be a thing.





